Voice
Supplement for chapter 17
Comprehensive and invaluable website: UNSW "Voice Acoustics"
New - Alexander Graham Bell's Voice
Recently resurrected from a damaged wax and cardboard disk - a wonderful achievement and article at Smithsonian.com.
Mel Blanc's vocal folds
Definitely worth a look/listen!
See also better vocal fold imagery at http://youtu.be/ajbcJiYhFKY * Video no longer available *
X-Ray movie of phonation
Another eye opener (as well as a good dose of radiation in 1962). At the end, hear the speaker say "Why did Ken set the soggy net on top of his deck"?
Falstad's Vowel Applet
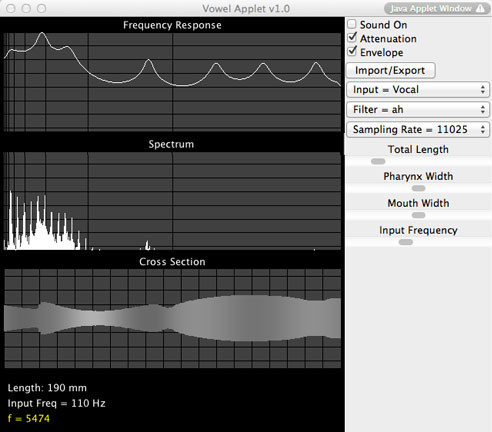
The Vowel applet written by Paul Falstad, is a relatively recent but very welcome addition to his suite of physics applets useful for sound studies and intuition. The source (also selectable to have different frequencies and spectral qualities, e.g. sawtooth, vocal-fold like, square wave, etc.) is at the left and the open end is at the right.
Aside from the ability to shape the cross section of the vocal tract, there is instant feedback on the resonances of the tube you have selected or drawn, shown at the top in a logarithmic (dB) plot called "Frequency response". The broad peaks seen there are the formants of the tube! Below it is shown the power spectrum ("Spectrum") for the tube driven by the chosen sound source at its left, in a linear plot. The larger tube resonances seen in the plot above it show up, as populated by harmonics of the sound source. The tube cross section is shown at the bottom. It can be changed in real time with the mouse, with simultaneous changes resulting in the sound. If the mouse is drawn across either the frequency response or spectrum windows with the sound on, the corresponding oscillating mode at the frequency chosen by the mouse is shown. Start with some of the higher frequencies, that are clearest, and move down to lower frequency. The modes are shaded in an apparently scaled way, so that on resonances does not seem "brighter" than in between them, but in fact the modes are stronger if they are within the bigger lumps (formants) of the frequency response at the top.
Praat
Praat, is designed by especially for speech by Paul Boersma and David Weenink, University of Amsterdam. It is a free, multiplatform sound analyzer with many tools available. A bit geeky at first, but quite nice when you get used to it. Do not be afraid to try it; everything you want to do can be figured out in a reasonable amount of time. It includes such things as sonogram analysis, pitch analysis (including multiple simultaneous pitches), gender transformations of recorded sound, and much more.
Jean-Francois Charle's MAX formants
Charle's MAX Formants is a "pure formant" synthesizer that can control the center frequency, gain, and frequency width of three formants independently, with sound of course to go along. It requires that you download the free MAX OSX and Windows runtime software here.
Sayonara Source Filter Model (17.4): Comments
We are not born with a fixed vocal timbre, or a fixed ability to project the voice. Voice training works, although there is also much misinformation surrounding it. Some of the mental imagery and terminology is quite harmless and may help singers and speakers with mnemonics that need not be faithful to physics.
Science depends on models of physical phenomena. Sometimes these models are the best one can do; sometimes they are mnemonics without real basis in fact. Even these can be useful if Nature has chosen to act in parallel with the model in spite of its baselessness. The model for lift of an airplane wing comes to mind. Supposedly, lift is generated by air needing to go farther traveling over the top of the wing (due to its curved upper surface) than over the bottom, necessarily traveling faster to meet its counterpart arriving from below, and, by Bernoulli's law, lowering its pressure on the upper side, generating lift. This fiction was known by its perpetrator, the great German aerodynamicist Prandl, to be quite wrong, but he said privately that novices must have something easy to grasp when thinking of flight.
Acoustics has its fictional stories like this too. Their danger is that teachers start to believe them and then their students do. For example, the source-filter model for vocalization has contemporary advocates (Chapter 17 Section 4) some of whom may understand that it is a only fictional model analogous to Prandl's wing model. The source-filter model ignores the key factor of resonance enhancement of sound, assigning the vocal tract the role of a mere passive filter -- i.e. suppressing some frequencies and letting others pass. This key fact seems almost totally absent when other shortcomings of source-filter theory are mentioned in some literature, as if the writer/speaker was not aware of resonance.
It is simply not widely appreciated that resonances do not require that the source do anything except vibrate/pulse almost exactly as it would have without the resonance; the magic of addition of amplitudes (source with returning waves) with power going as the square of the amplitude does the rest. The extra work that a physical source does on resonance is real, but the amount usually a tiny fraction of the work being done against more mundane sources of friction.
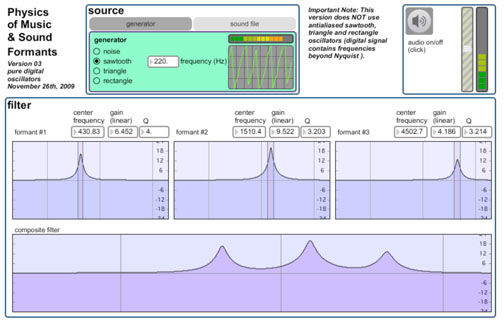
A pulse of pressure is initiated in a long half open tube, by a sudden injection of air at the closed end, akin to what the vocal folds do each time they open.
The pulse moves out at the speed of sound toward the open end. It's power spectrum is broad, corresponding to the time-frequency Uncertainty Principle and Fourier analysis: many sinusoidal waves, each of a different frequency, are needed make the short pulse. If we place a microphone at the source, the power spectrum may be computed after the first, initial pulse has subsided. This is the ``source'' power spectrum, seen at the bottom of the image.
Will the reflections off the end merely dig holes in this source spectrum, as source-filter theory would have us believe? No -- we have by now firmly established that reflections -- echoes -- initiate the generation of resonances that are "louder" than the source. Other parts of the source power spectrum are depleted, (in order to build up resonance peaks higher than the source spectrum-) i.e. the sculpting principle.
The power spectrum will be redistributed into broad peaks and sharp valleys. Crucially, the power spectrum has the same area, but it has been depleted in some regions and built up in others. This is not what a filter does; a filter only depletes. This is reallocation of sound power from one part of the spectrum to another. It makes some spectral regions louder, at the expense of others. It does not increase total sound power. The vocal folds are already the beneficiary of the proximity resonance effect, wherein the confinement of sound by the larynx reinforces the sound.
This UNSW site on he voice *typo?* gives too much credence to the source-filter model but is otherwise quite nice.
Sine-wave speech
Sine waves are very narrow in frequency content compared to a formant of the vocal tract. Can they nonetheless somehow replace formants and make speech intelligible using just a few sine waves? This question is addressed at Al Bregmans site.
This is but the 23rd demo of 41 on this interesting site highlighting ideas and research in Auditory Scene Analysis.
The Haskins Laboratory at Yale University has an informative website; in connection with sine wave speech (replacing formants and their variation in pitch over time with sine waves varying in frequency the same way) see/hear this. * dead link *
Multiphonics
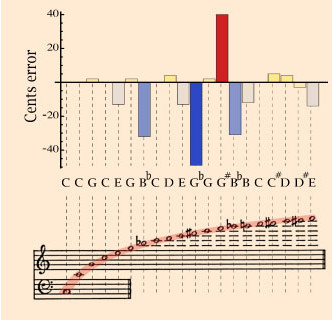
Pseudo vs. true multiphonics:
A typical pseudo multiphonic is a periodic waveform with remote partials being very strong; distant partials with a relative dearth of power between them seem to our ears not to be especially musically related to each other. One of the reasons for this, we know from this figure in Chapter 26, is that overtone partials of a given note do not in general fall on established notes of the musical scale; they may be close to them but sharp or flat.
Physically, it is easier to imagine vibrations of vocal folds, reeds, lips, etc. that are at least periodic; a sharp formant of the vocal track can then sharply amplify a single high partial, as in the Tuvan singing discussed in Chpt. 17.
A pseudo-multiphonic clarinet note was produced by Jean-Francois Charles; you can hear it here; its periodic waveform is seen below.


A true multiphonic waveform is much harder to produce in a musical source such as a clarinet, since you have to get the reed vibrating at two (or more) incommensurate frequencies. Nonetheless below we have another Jean-Francois Charles sound file of a true multiphonic clarinet gliss; the incommensurate nature of the frequency relation of the partials (for most of the glissade - sometime they pass through rational relations as one frequency slides) is proven by the fact that one of the partials is made to slide up and down whilst the other is held fixed. The fixed frequency is seen at the bottom of the sonogram of this sound file, and various partials of the glissade are seen above it.
Vocal tract tuning by sopranos
Important work by the University of New South Wales group is reported here, with lots of sound files you can listen to and analyze.
Project: Testing your own formants
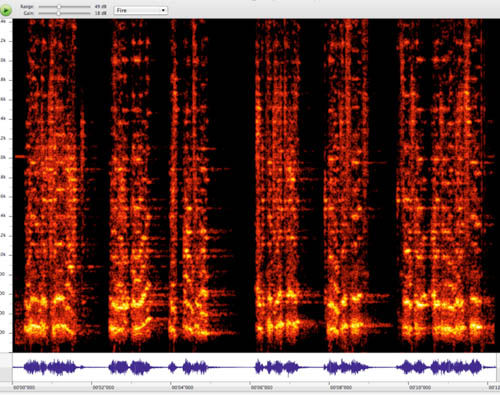
Fire up your laptop and record your voice, performing a sonogram analysis:
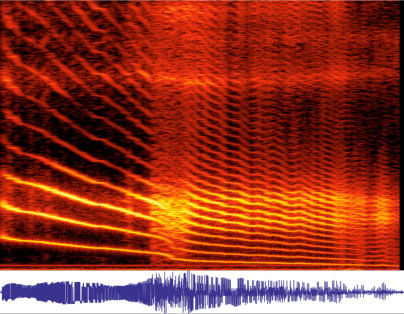
say ahhhhh... with sliding frequency:
Note the preservation of the formants (bright bands running horizontally) as the driver - the vocal folds - changes frequency, causing the overtones to "slide through" the formants.
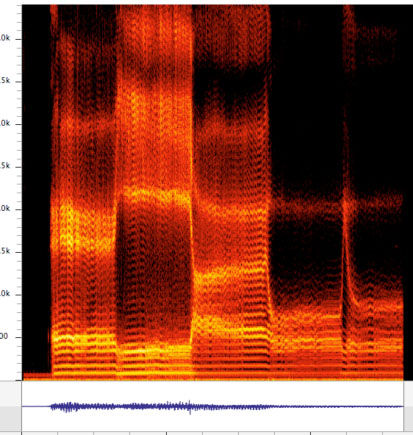
Say a-e-i-o-u in a low, croaking voice (getting thereby lots of harmonics in a short span of frequencies, to populate the formants, that you will note are radically different from one vowel to the next.
At the right, there is one vertical band for each of the five vowels; the low frequency croaking sound lights up the formants with many harmonics.
Tuva singing on YouTube:
Please click here to see the video (Author has disabled embedding it on other sites)
Singer's formant
Vocoder
Suppose you take a voiced sentence or song and extract the changing formants, keeping track of frequency of the formants at successive times. This record, which does not keep track of the individual partials (harmonics) which populate the formants, is called the "modulator" signal. Then these formants are imposed on another signal, the "carrier", which is usually taken to be formant - free but rich in harmonics. The powerin the carrier is enhanced in the formant frequency ranges, and decreaedt in between. The new sound file of the modulated carrier can sound like robotic speech, but is understandable even if the frequencies of the partials in the carrier stay the same frequency, which is certainly not true when most people speak.
Nasal Cavity
We admit to giving short shrift to the role of the nasal cavity in Why You Hear What You Hear, just as most sources do. The excuse for this might be brevity, but the real reason is complexity. Clearly, we sound different with a cold (that raises another issue: are the sinuses involved?) and when pinching the nose, when the nose is closed off.
The exception to the complexity issue (that is caused by two ports simultaneously open to the outside, nothing computers can't handle but more difficult to explain qualitatively) when the mouth is closed off and only the nose is open; this happens for example in English for words containing "in" and "im". Try them, and you will notice you close off the airflow through the oral cavity with your tongue.
The video extols the virtues of singing with the nose closed off, that is possible to learn without a clothespin.
*** The video https://www.youtube.com/watch?v=IvBvmyg8j3A is no longer available on YouTube ***
Here is a sketch of a more realistic model for the voice, for someone without a cold:

Project:
Analyze the difference in sound and formants with and without your nose closed.
Speaking machines
Wolfgang von Kempelen's speaking machine.
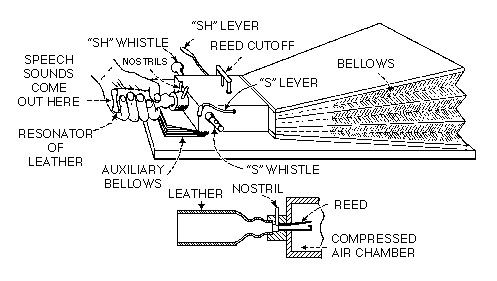
The final version of von Kempelen's machine(1791) is preserved to this day.
It was kept at the k. k. Konservatorium für Musik in Vienna until 1906, when it was donated to the Deutsches Museum (von Meisterwerken der Naturwissenschaft und Technik) in Munich, that had been founded three years before. There, it is exhibited in the department of musical instruments.
Joseph Faber's Amazing Talking Machine (1830-40's).


Talking Piano
By carefully timing the notes on a piano (definitely a job for a computer) it is possible to mimic the sonogram of vocal speech, and thus may something like speech come out of a piano! The video below makes that clear - by example.
A sonogram of the talking piano, showing speech-like patterns (although based on fixed frequencies, i.e. piano notes, as can be seen).
Project: Making a vowel resonator

Excellent web site describing the construction of simple vowel resonators. One variation you should consider is making the soft parts "squeezable" so you can alter the tube's shape and perhaps diameter. The key idea is getting a duck call (or making one) and hooking it to various pipes.
Here is a page of animations pertaining to human sound, from Joe Wolfe of UNSW. On it you will be able to download a dozen or so files, one of which is a vowel resonator that he drives with a pulsed source and shows the effect of pinching the tube. After downloading, go the folder and click on the .html file.
Project: Vocal tract resonances (formants) via a tube and speaker
A convincing experiment relating to the source spectrum and vocal tract resonances can be done with a small round loudspeaker (such as some computer speakers that sit on desktops). It should be removed from its housing in order to fit snugly in a tube. Draw a sharp, triangular spike waveform using Falstad's Fourier applet, set the frequency for about 70 -100 Hz. Play it out of one of the speakers. Make a paper tube about 6 or 8 inches long to fit the diameter of the speaker, and alternately hold it against the speaker and away from it. The enhancement in the loudness of the tube resonances is apparent to the ear, and if recorded in Audacity, RavenLite, etc. with the microphone near or in the tube, the clear increase in loudness over the source loudness will be quantitatively proved. The resonance effect is more dramatic if a ca. 2 in. speaker is removed from its housing, hooked up to the leads and held at the end of the tube; this eliminates much of the sound radiation from the resonator box of the speaker, and it more closely mimics the vocal folds at the end of the vocal tract.
Project: Vocal tract resonances (formants) via Ripple
Here we demonstrate modeling of a vocal tract and determining its resonances (formants) using the Harvard University modified version of Paul Falstad's Ripple. The idea is to draw a vocal tract, launch a sharp pulse of sound at its base, and record the amplitude outside the mouth as a function of time. This amplitude can be saved as data in Ripple, that is uploaded as a plain text file. Then a little bump in the road must be surmounted: how do you turn the data into sound? The author used Mathematica to do it, but it is a little tricky to build a CDF applet, since commands to read the file structure of the location of the data file need to be executed, and some details about which column of data is being read, etc. A snippet of code is given at the end for anyone familiar with Mathematica.
Here is the set-up in Ripple, and a snapshot after a short time has evolved.
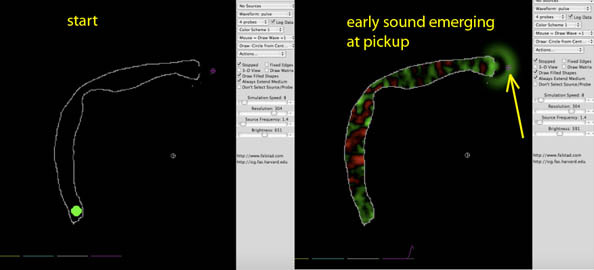
The signal received by the pickup at the mouth (arrow above) is shown below at the right, and the left reveals the sonogram of that signal. Note the prominent resonances or formants; these are sharper than in the human vocal tract, certainly in part because there is no friction or other dissipation at the walls in this simulation. Click below to hear the sound. One reason it doesn't sound very much like voice is that the initial pulse has many unrealistically high frequencies in it. Nonetheless, typical formant frequencies are seen.

Mathematica hints for making a .wav file from your Ripple data
First, set your directory (in Mathematica), then the code follows:
SetDirectory["/Users/yourusernamehere/Documents/mysounds"] (*or whatever your directory path is*)
aa1 = Import["yourfile.txt", "Table"]; (*this is the text file from Ripple, residing in the sounds folder here*)
bb1 = Transpose[aa1];
p2 = ListPlot[ { bb1[[2]]}, Joined -> True, PlotRange -> All]; (*here the argument is [[2]], but you need to select the column where the data you want is; here it was the second column*)
xx = ListPlay[.4*bb1[[2]], SampleRate -> 1*12*4096, PlayRange -> All]
Export["yourchosenfilename.wav", xx] (*here you can experiment with SampleRate*)
Phonetics
UCLA phonetics lab with many example files and demonstrations.